(Updated October 16, 2018) With the election coming up in the next week and this page getting more traffic, I decided to do a quick refresh of the data used in this post up to and including October 15. Changes are relatively few, and as this site is a github repo, can be tracked via commits to this post.
The 2018 Municipal Election in Vancouver
On October 20, a relatively small portion of Vancouverites will vote to elect a mayor, 10 city councillors, 7 park board commissioners and 9 school trustees. Municipal elections do not receive the fanfare or attention of federal or provincial elections and see lower turnouts, but they are an important determinant towards the policies that affect the everyday lives of city residents.
With 21 candidates for Mayor and 77 candidates for Council, there’s a lot to parse through. The City of Vancouver provides candidate profiles, and most of the candidates and parties who are likely to receive the most votes have already released their platforms.
While there are certainly a number of interesting and unique independent candidates looking to run for Mayor, all existing polling suggests that there are six candidates with a realistic shot at being elected: Kennedy Stewart (Independent), Ken Sim (NPA), Shauna Sylvester (Independent), Hector Bremner (Yes Vancouver), David Chen (ProVancouver), and Wai Young (CoalitionVan).
Mayor Twitter
Campaign financing reforms introduced prior to this election have meant that there is less money available to campaigns, and, therefore, less promotion and advertising of candidates ahead of the election. Recent elections around the world have demonstrated, for better or worse, the effectiveness of social media platforms like Twitter in raising candidate profiles and bringing out supporters. All six top mayoral candidates are relatively active on Twitter, and appear to have increased their online participation with the election drawing nearer. Fortunately, Twitter is the best platform for analysis with it’s public facing content, relatively generous public APIs, and a number of excellent tools developed to extract and work with tweet data.
Highlights and caveats
There’s a few key takeaways from this post that I want to highlight here:
- Until we have election results, Twitter performance is not indicative or predictive of anything in this race, but it is an interesting way to look at things.
- Twitter engagement does not necessarily mean much on its own as it can reflect engagement with a built-in and captive audience, especially when it comes to messages using specific hashtags.
- That said, all things considered, as a candidate you would like to see an increasing trend in tweet engagement.
- Shauna Sylvester is trending in the right direction but has a long ways to go to match Kennedy Stewart’s overall numbers.
- Bremner and Sim need to tweet more, if only so that there’s more of a text corpus to analyze.
- Unfortunately the Twitter API makes it challenging to get the number of replies to a given tweet so we are unable to calculate “ratio” for all of the thousands of posts by the six candidates, but we’ll always have this one from Wai Young.
Bike Lanes are divisive and discriminatory. They discriminate against seniors, single Moms and many other groups. They are a private roadway system that have been built to benefit a very specific few in society. 1/3 #commonsense #vanpoli #VanElxn18 #Vancouver #coalitionvancouver
— Wai Young (@WaiYoung) September 5, 2018
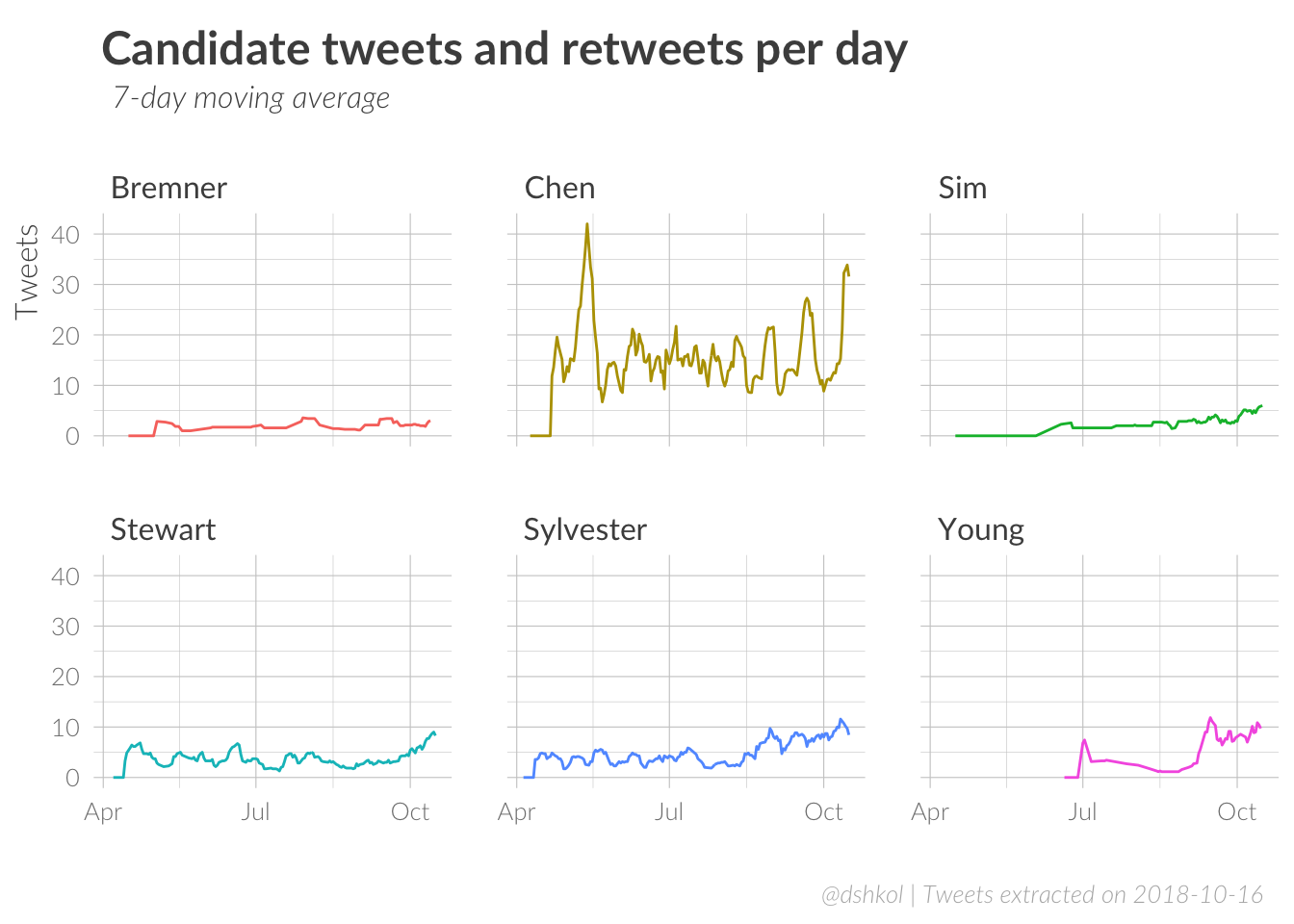 Of the six, Chen has been the most active tweeter since April 2018 with 2943 tweets, more than three and five times as many as the next prolific tweeters in Sylvester and Stewart, respectively. Bremner, Sim, and Young, in comparison are much less active tweeters, but all appear to have increased their tweeting as the election draws closer.
Of the six, Chen has been the most active tweeter since April 2018 with 2943 tweets, more than three and five times as many as the next prolific tweeters in Sylvester and Stewart, respectively. Bremner, Sim, and Young, in comparison are much less active tweeters, but all appear to have increased their tweeting as the election draws closer.
Engagement trends
We can measure visible engagement by adding up the number of retweets and favourites to look how those tweets are performing, but its not always indicative. A viral bad tweet (see above) will have a huge audience and will inevitably see more visible engagement as someone, somewhere, will find something they like in any opinion. Measuring the engagement rate of tweets requires knowledge about the audience size and reach of each tweet, which is not something available publicly, so this is an imprecise measurement, but it can serve as a proxy for audience growth.

Changing sentiments
Sentiment analysis of Twitter data is a well-traversed form of analysis. Briefly, sentiment analysis relies on algorithms that work existing natural language corpuses to estimate the positive or negative score value of words and sentences. The sentiment of a tweet is estimated by adding up the sentiment scores of the individual words within that tweet. A higher score suggests a more positive sentiment. These sentiment scores are useful as a quick meta analysis of the high-level approach each candidate takes in composing their tweets.
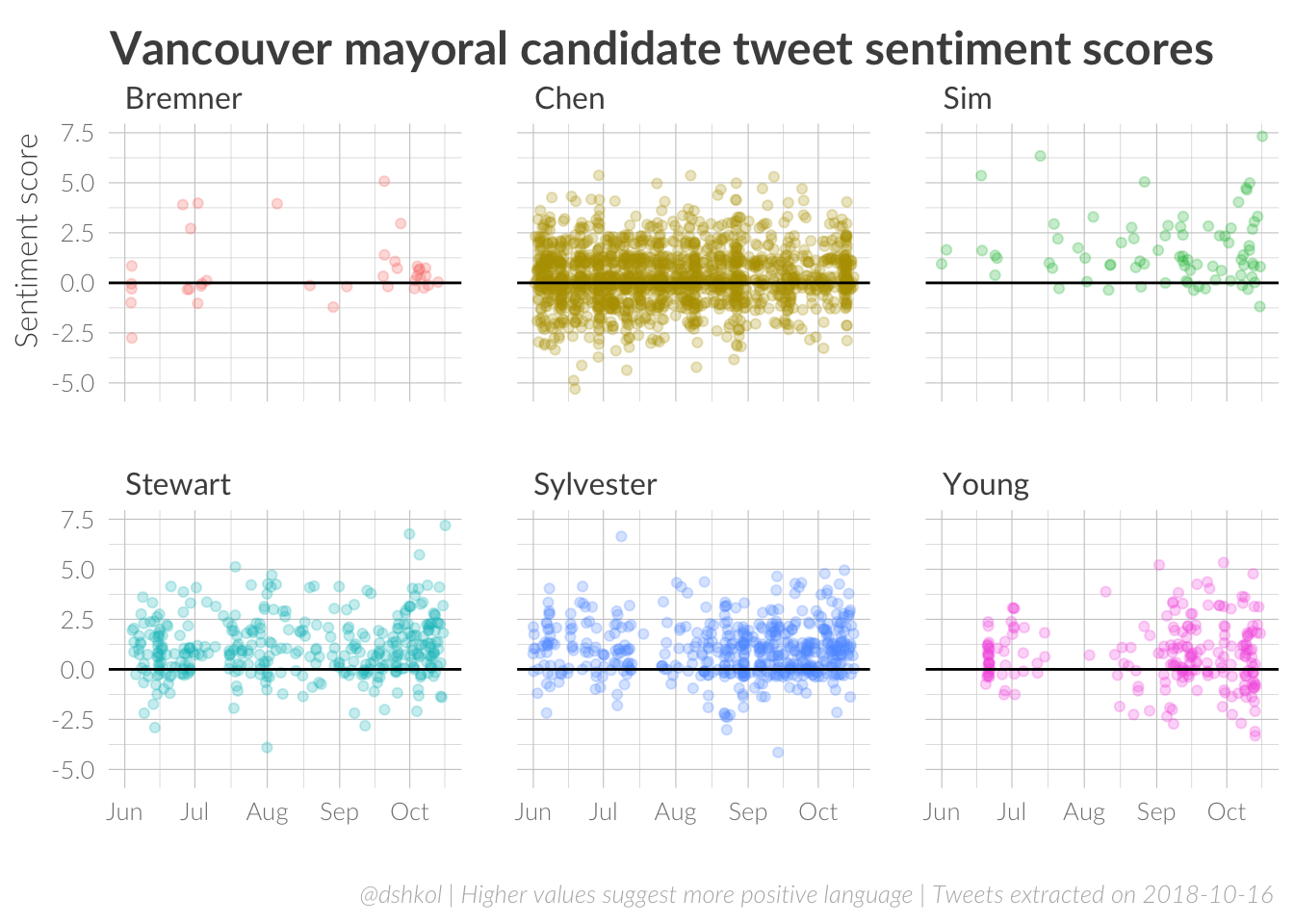 While all candidates have tweets classified as positive and negative, it is Chen who is the candidate who appears to rely the most on negative sentiment tweets.
While all candidates have tweets classified as positive and negative, it is Chen who is the candidate who appears to rely the most on negative sentiment tweets.
Both positive and negative messaging are viable approaches to political messaging and revealed trends in tweet sentiment can help inform of us which way candidates appear to be focusing their messaging as the election draws closer.
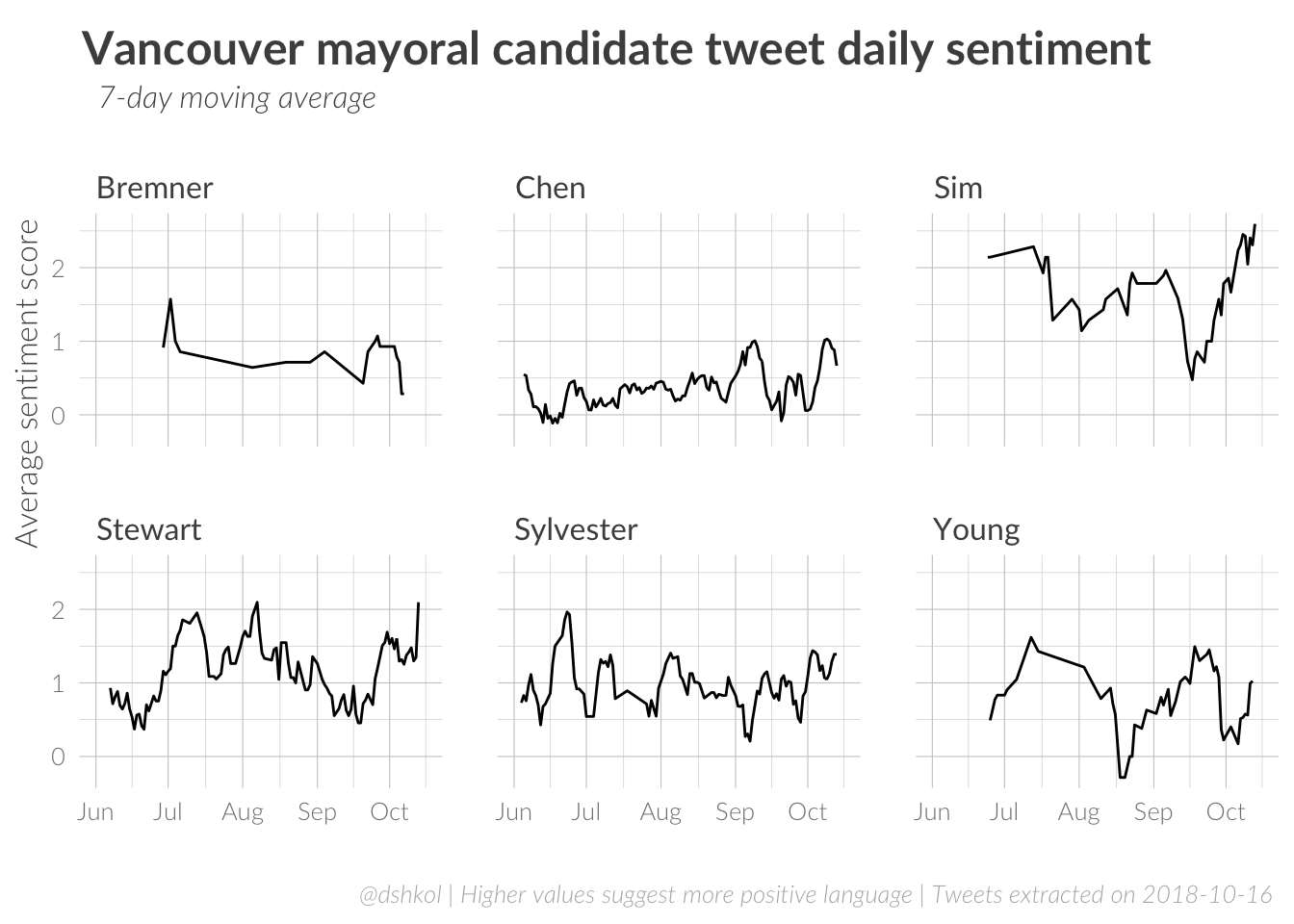
There are some well-documented weaknesses in estimating sentiment of human speech. For example, the majority of sentiment lexicons would classify both “bad” and “ass” as words contributing to a negative sentiment, not knowing that “bad ass” actually has a positive connotation. There are ways around this with more sophisticated n-gram based sentiment approaches, but this sentiment analysis approaches do not account for this.
Tweet text characteristics
Text is structured data with recurring patterns that are typically unique to a person. Even within the confines of 140 or 280 characters, the idiosyncratic linguistic patterns of different tweeters will often show up. The last few years have seen the development of numerous powerful and adaptable tools and libraries for natural language processing (NLP) in R that make it straight-forward to do analysis of large bodies of text at scale. We can use these tools to see if there are distinct patterns in how these six candidate use language on Twitter, and, further down, what kind of language they use.
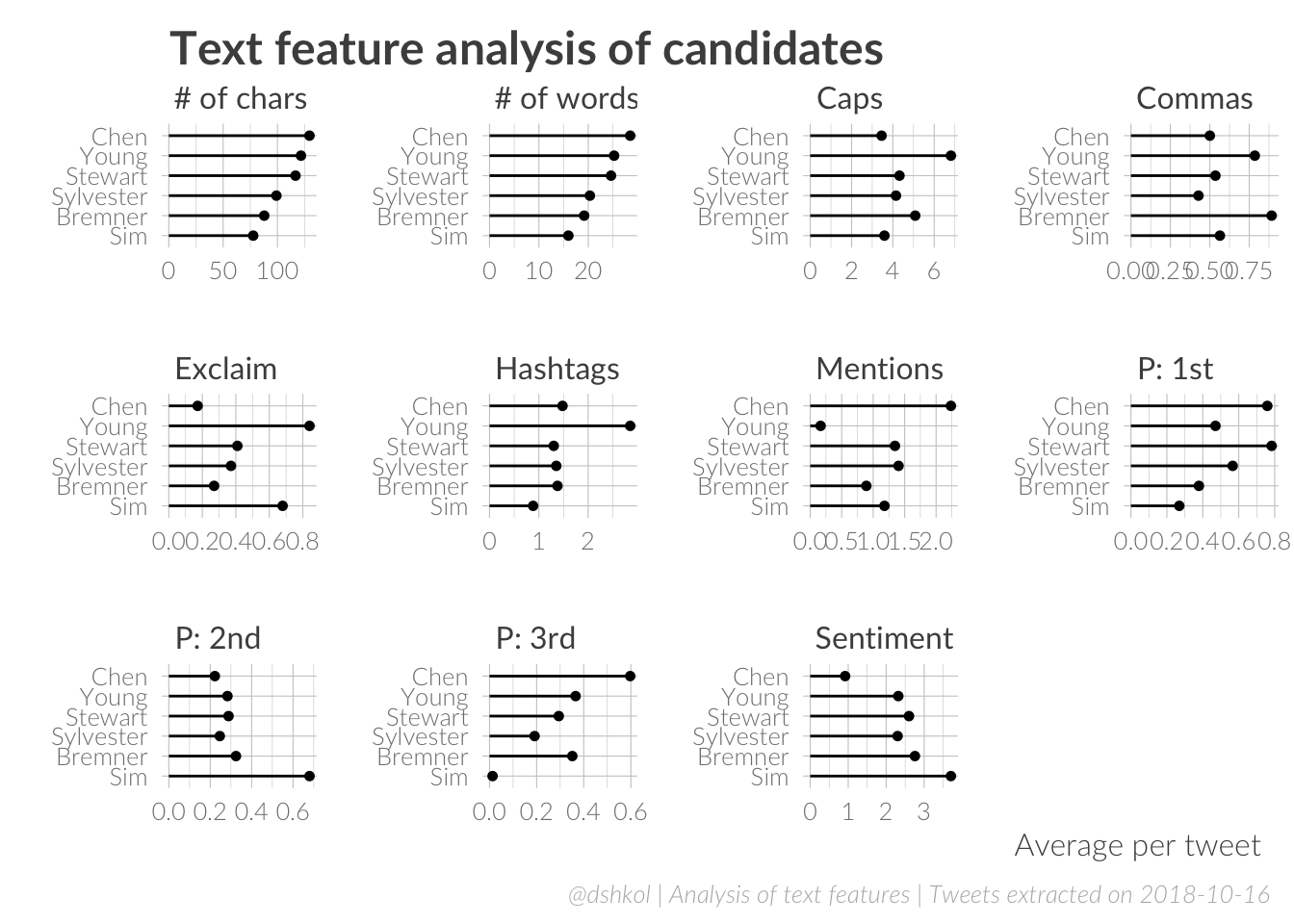 We already saw earlier that Chen’s tweets are, on average, the most negative and Sim’s were the most positive. But it is also interesting to see that Chen stands out in a number of other ways as well. His tweets are the longest, the most verbose, the most likely to mention other users, and the most likely to take the third person perspective (“they”). Wai Young likes hashtags and exclamation marks the way Bremner likes commas. While both Stewart and Sylvester are running as independents, the former appears to be far more likely to adopt the first-person perspective in their tweets.
We already saw earlier that Chen’s tweets are, on average, the most negative and Sim’s were the most positive. But it is also interesting to see that Chen stands out in a number of other ways as well. His tweets are the longest, the most verbose, the most likely to mention other users, and the most likely to take the third person perspective (“they”). Wai Young likes hashtags and exclamation marks the way Bremner likes commas. While both Stewart and Sylvester are running as independents, the former appears to be far more likely to adopt the first-person perspective in their tweets.
Tweet language differences
Individual words or word-like components can be extracted from any text corpus, such as tweets, using a process called tokenization. Again, with the NLP tools at our disposal nowadays, this is straight-forward and is further aided by the existence of Twitter specific token-parsers lexicons of common stop-words that are not interesting for analysis (“it”, “the”, etc.). This is less of an issue with mayoral candidates who are more likely than the average Twitter user to post in standard English, but it allows for generalization of this process to other Twitter users who may use non-standard English terms (“smh”, “wtf”, “:)”, etc.).
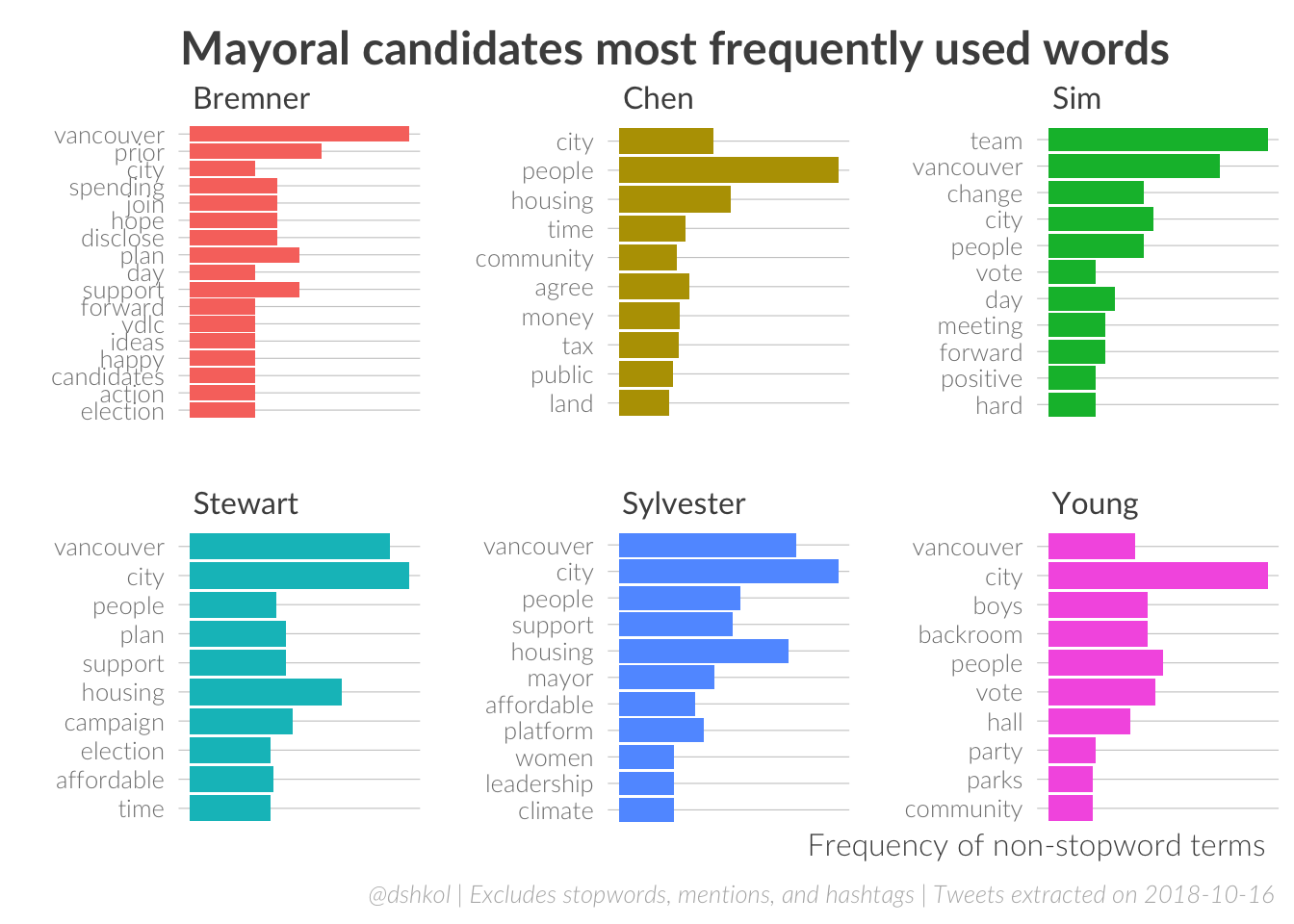 Token analysis of the candidates’ tweets shows a fair bit of similarity: Vancouver, city, people regularly appearing as the most frequently used words by almost all candidates. Other differences do appear between candidates, however. Consider Sim’s emphasis on team, Bremner’s hope … and prior(?), Chen’s tax and money, and Young’s bike. Both Stewart and Sylvester really emphasis housing in their tweets, as well as Chen to a lesser extent.
Token analysis of the candidates’ tweets shows a fair bit of similarity: Vancouver, city, people regularly appearing as the most frequently used words by almost all candidates. Other differences do appear between candidates, however. Consider Sim’s emphasis on team, Bremner’s hope … and prior(?), Chen’s tax and money, and Young’s bike. Both Stewart and Sylvester really emphasis housing in their tweets, as well as Chen to a lesser extent.
As this text comes from tweets, we can combine it those tweets’ engagement numbers to see if any of these words are more likely to lead to likes than other words for each candidate.
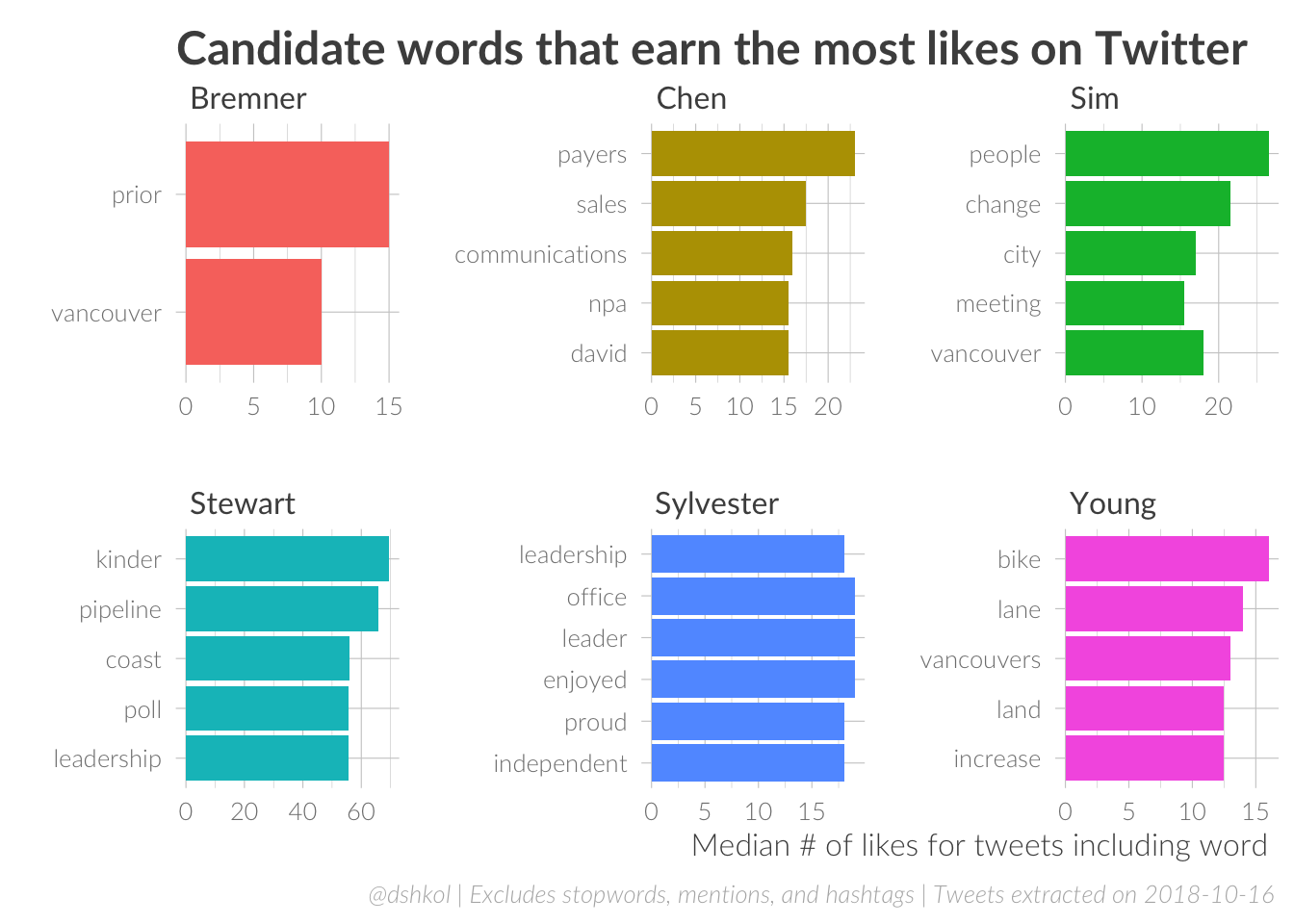 A few things immediately stand out that should be obvious to anyone who has paid attention to this race to this point: Stewart’s audience cares about the coast and his plan to fight the Kinder Morgan pipeline expansion. Sylvester’s audience cares about the Broadway Millennium Line extension. Young’s tweets about bike lanes appear to particularly resonate, Sim is earning engagement for being Sim and not for what he tweets, and Bremner needs to tweet more so that his data can be quantitatively meaningful.
A few things immediately stand out that should be obvious to anyone who has paid attention to this race to this point: Stewart’s audience cares about the coast and his plan to fight the Kinder Morgan pipeline expansion. Sylvester’s audience cares about the Broadway Millennium Line extension. Young’s tweets about bike lanes appear to particularly resonate, Sim is earning engagement for being Sim and not for what he tweets, and Bremner needs to tweet more so that his data can be quantitatively meaningful.
(Oct.16) Update: not too many changes here with the exception of Sylvester who appears to have greater amounts of positive engagements for her recent “leadership”-focused posts. This coincides with a significant increase in the average number of engagements for Sylvester’s posts but it’s not obvious whether there is a causal relationship there.
A note on data and tools
Putting together the analysis in this post takes a lot less time than it looks like thanks to several highly useful R libraries that do most of the heavy lifting here. Tweets for each candidates’ timeline were extracted using the Twitter API and the rtweet package. Sentiment analysis was performed using the syuzhet package, while text feature characteristics were extracted using the aptly named textfeatures package. Finally, words and tokens were extracted from text using the tidytext package. The authors of that package have an excellent textbook with instructions and examples that can be viewed for free at https://www.tidytextmining.com.
As usual, the code for data retrieval, data processing, and for the visuals in this post is available on Github.